Documenting, testing, and moduling
By Robert Laing
A nice thing about Prolog, specifically SWI Prolog, is there isn’t the cacophony of competing document generating systems, unit testing frameworks etc as there are for, say, JavaScript.
Nevertheless, getting to grips with PLDoc, PLUnit, along with SWI Prolog’s modules etc is not that easy, so I’ve made these notes for myself and anyone else interested.
The very basics of PLDoc is it can be launched as a web server either from within the swipl repl with
doc_server(4000). or from the bash shell with swipl --pldoc myfile.pl. See
Running the documentation system for details.
Project Home Page
There is a hierarchy in PLDoc, which it terms views. This screen shot is the top level view, called Directory.
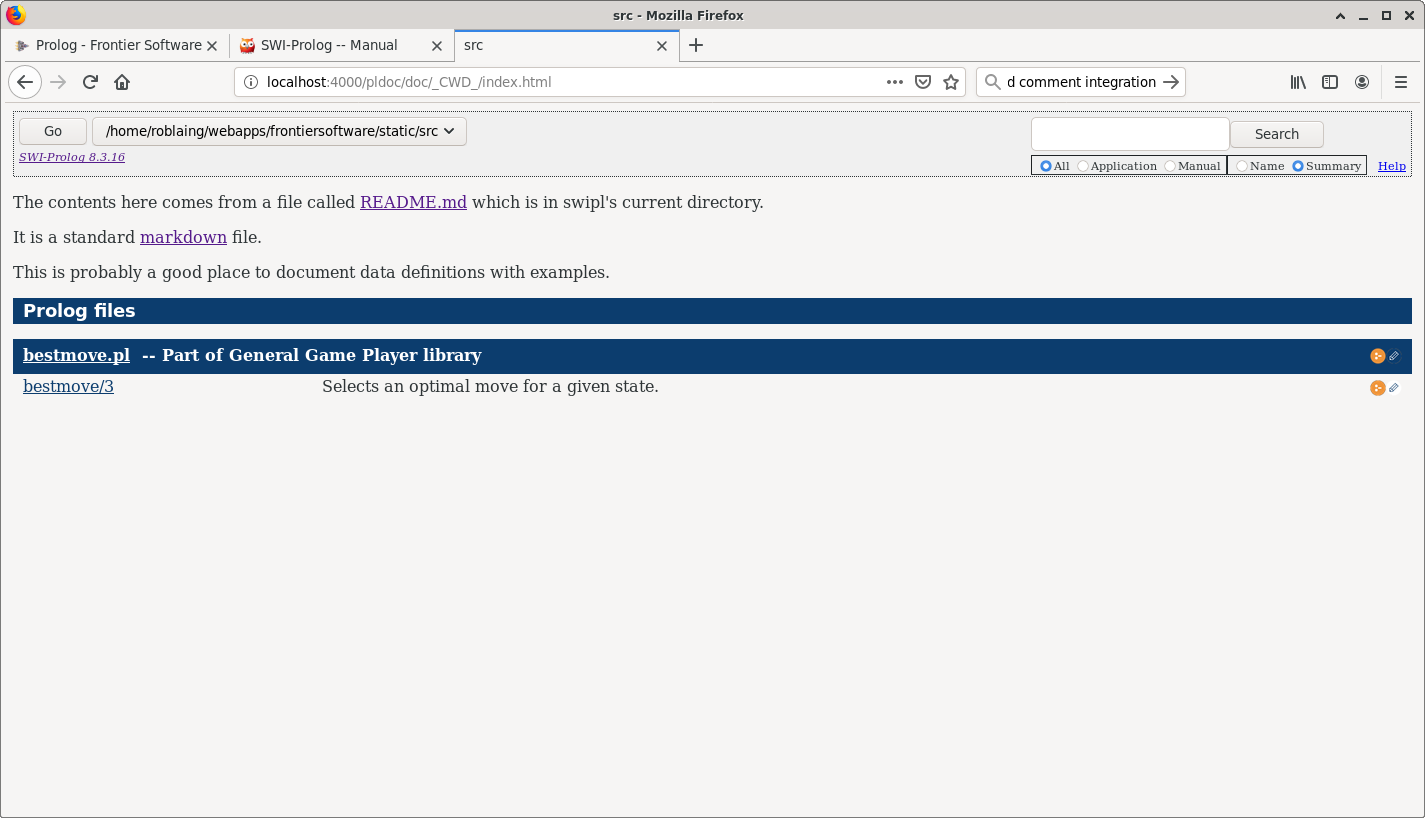
PLDoc looks for a file called README.md. You don’t have to use markdown, but since SWI Prolog’s support for markdown has steadily grown since I started using it, it’s what I recommend since it makes github easy to integrate.
I’ve kept my README.md short and simple for this example.
Next there’s an automatically generated table of Prolog files which have been loaded with consult(:File) or use_module(+Files) to make PLDoc aware of them. To keep things simple, I’ve only loaded bestmove.pl which has a single public predicate. The top of this file looks like so:
:- module(bestmove, [bestmove/3]).
/** <module> Part of General Game Player library
This is part of an AI library for games as described at [General Game Playing](http://ggp.stanford.edu/notes/cover.html)
@author Robert Laing
@license GPL
*/
Note PLDoc’s File (module) comment comes after the module(+Module, +PublicList) statement.
The directory page uses the above to give a short description of the module, and lists its public predicate with its purpose statement which I’ll explain below.
There are quite a few quirks to SWI Prolog’s modules which I’ll touch on briefly here:
- By convention in SWI Prolog, the first argument, +Module, is the same as the filename without the
.plsuffix. This is only a convention, in contrast with say Erlang where the module and filename being the same is an enforced language rule. - +PublicList is a list of functors which is Prolog jargon
for a list of
PredicateName/Arity(I’ve misused the word functor as a synonym for predicate name, and only recently became aware it implies a/3or whatever suffix). The +PublicList equates to what How To Design Programs calls a wish list, which is vital to design thinking. To keep things simple in an introductory example, there’s only one item in this list here, which again has the same name as the file and module. - Modules can contain meta-predicates whose notation is confusingly similar to the argument mode indicators used in documentation. Though related, they are not the same.
- Clients of a module can either add all predicates in +PublicList to the global built-in set with use_module(+Files) or specific ones with use_module(+File, +ImportList).
- SWI Prolog mercifully does not make a fetish out of hiding predicates in modules which are not publicly listed. Private
predicates can be accessed as Module:Predicate(Arg1, Arg2, …) — ie colons in SWI Prolog are similar to
the namespace delimiting dots in Python etc — which I find handy to generalise different games by addressing
them as
chess:init(State),checkers:init(State), … which wouldn’t be possible if the language insisted on one globalinit(State). Logtalk developer Paulo Moura argued in stackoverflow this colon naming convention makes SWI Prolog’s modules akin to objects. - +File can either be a pathname (bad for portability because it assumes different machines have exactly the same directories)
or
library(module_name)which relies on autoload and can be added to in$HOME/.config/swi-prolog/init.pl.
Module Page
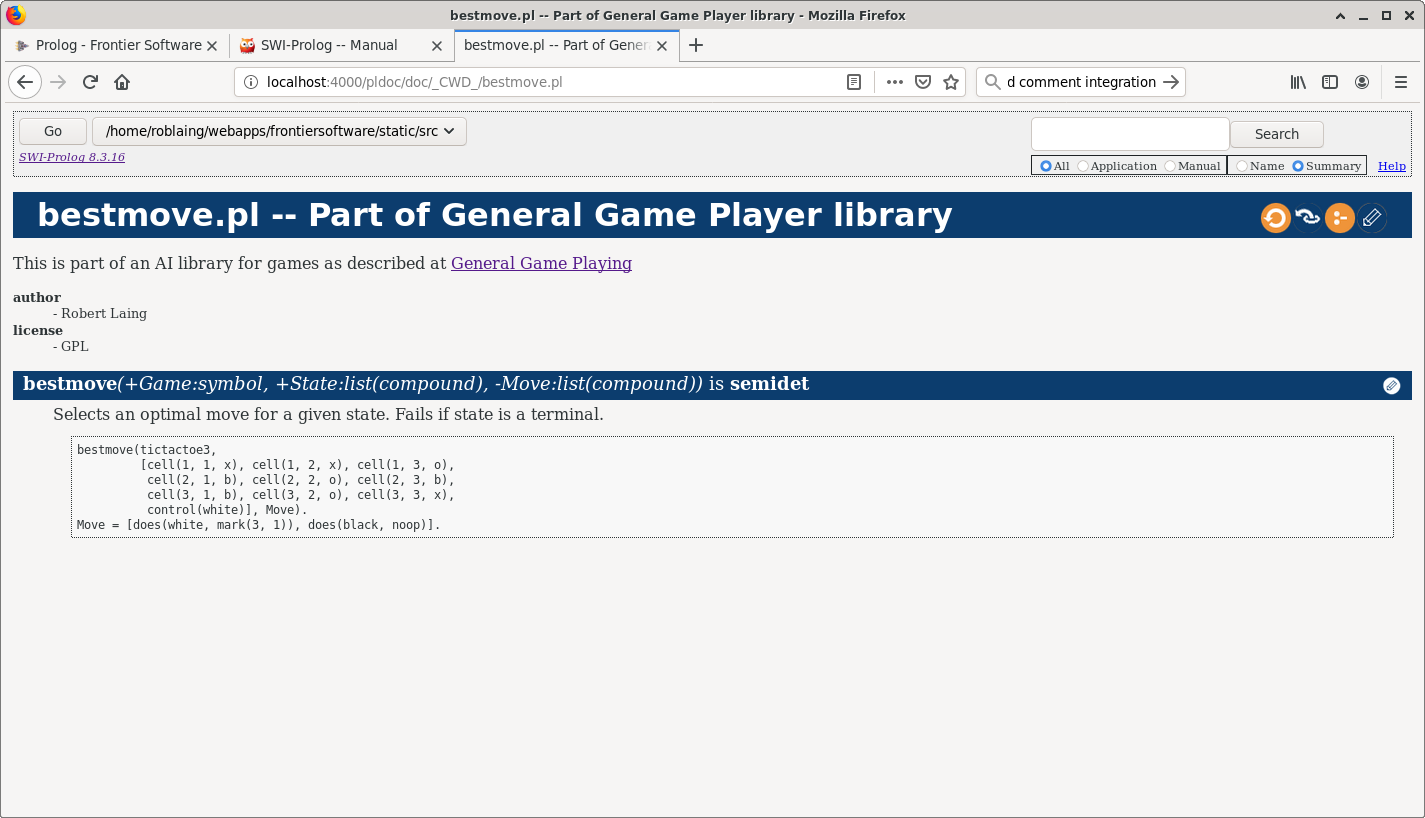
Structured comments
PLDoc supports two styles of structured comments: JavaDoc or traditional Prolog percentage sign.
I favour the JavaDoc style (since it makes flipping between JavaScript’s JSDoc easier, and saves percentage signs for comments which are simply comments), and my structured comment for this example looks like so:
/**
* bestmove(+Game:symbol, +State:list(compound), ?Move:list(compound)) is semidet
*
* Selects an optimal move for a given state. Fails if state is a terminal.
*
* ```prolog
* bestmove(tictactoe,
* [cell(1, 1, x), cell(1, 2, x), cell(1, 3, o),
* cell(2, 1, b), cell(2, 2, o), cell(2, 3, b),
* cell(3, 1, b), cell(3, 2, o), cell(3, 3, x),
* control(white)], Move).
* Move = [does(white, mark(3, 1)), does(black, noop)].
* ```
*/
bestmove(Game, State, []). % Stub to be developed into working code later.
There’s quite a lot to unpack and tie back into How To Design Programs 6-step recipe. To keep things simple, I’m skipping the first data definition step (though it’s the most important step, but covering it would turn this into a book).
The focus is mainly on the second step header — which combines three important steps: writing a signature (also known as specifications or contracts), a one line purpose statement, and an illustrative example which needs a stub to get an initial, failing, test to work.
Step 3 — writing illustrative examples — bleeds heavily into the final step, testing. These lead to test-driven development which is a difficult habit to develop for most of us weaned on diving into small problems rather than big picture designing.
I prefer example-driven to test-driven since the first thing I tend to look for in documentation are simple examples, so writing examples first leaves good documentation in its wake besides encouraging proper design.
A good habit to get into is to have my_module.pl open in one tab of your favourite text editor and my_module.plt in another,
developing the code and the tests concurrently. In the my_module.pl file, initially concentrate on the wish list of predicates
and only writing structured comments like the one above for each with a stub — something like
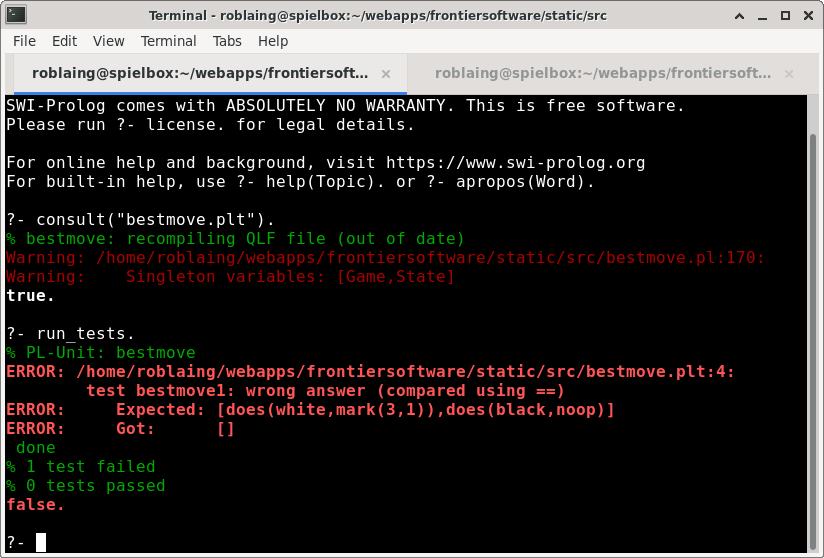
bestmove(Game, State, []). which will result in Warning: Singleton variables: [Game,State],
a handy reminder that this is just work in progress.
For my example, my initial bestmove.plt looks like this:
:- begin_tests(bestmove).
:- use_module([bestmove, tictactoe]).
test(bestmove1, Move == [does(white, mark(3, 1)), does(black, noop)]) :-
bestmove(tictactoe,
[cell(1, 1, x), cell(1, 2, x), cell(1, 3, o),
cell(2, 1, b), cell(2, 2, o), cell(2, 3, b),
cell(3, 1, b), cell(3, 2, o), cell(3, 3, x),
control(white)], Move).
:- end_tests(bestmove).
I made some edits to the above code following some feedback from SWI Prolog’s main developer Jan Wielemaker
on Discourse.
At the end of this document I introduce qcompile(:File) which speeds
up SWI Prolog scripts by compiling them. I originally wrote use_module(["bestmove.pl", "tictactoe.pl"]) and suggested
changing that later to use_module(["bestmove.qlf", "tictactoe.qlf"]). Jan explained that happens automatically if you
list filenames as symbols without any suffixes. He also advised making the expected result the second argument of
test rather than an assertion(:Goal).
The stub serves to produce a failing test:
Writing illustrative examples before diving into the code is a difficult habit to develop, but truly turns one into a much better programmer long term.
I initially wished PLDoc and PLUnit were more integrated, like say Python’s
doctest where tests inside comments are run, either silently or verbosely
if invoked with python example.py -v.
Subsequently, I’ve come to realise that while you only want one or two illustrative examples inside a structured comment,
the number of tests in the test file tends to explode. For instance, the bestmove predicate I wish for is what
Prolog terms semidet — it must either return one move without choice points or false if its input state
is a game over state. So that’s the next test to write before diving into the code.
What?
How To Design Programs Steps 2 and 3 can be summarised as initially focusing on what you want to achieve, pushing aside until later how you are going to do it. This is a philosophically powerful idea which applies to anything, but lets limit ourselves to software development here.
The late Patrick Winston in his forward to Ivan Bratko’s Prolog: Programming for Artificial Intelligence wrote:
In broader terms, the evolution of computer languages is an evolution away from low-level languages, in which the programmer specifies how something is be done, toward high-level languages, in which the programmer specifies simply what is to be done. … Prolog, on the other hand, is a language that clearly breaks away from the how-type language, encouraging the programmer to describe situations and problems, not the detailed means by which the problems are to be solved.
If any what programing languages exist, I’m not aware of them — Leslie Lamport’s TLA+ is probably the closest, but no cigar since it’s primarily intended to be a design aid, not an end product.
Documentation is the closest we get to what programming, which is why good documentation is more important than code. We are stuck with bad what decisions forever whereas the lines of how code can steadily evolve, hopefully getting shorter and quicker as our knowledge grows.
Specification pseudo code
The bestmove(+Game:symbol, +State:list(compound), -Move:list(compound)) is semidet line is what PLDoc calls a
declaration header and is a specification language
described in the documentation as
Notation of Predicate Descriptions. It involves
knowing SWI Prolog’s types, mode indicators ++, +, -, --, ?, :, @, !, and behaviours det, semidet, and nondet.
Types
The How To Design Programs recipe advises programers to first write a signature simply listing the types a function is going to consume and the type it returns, initially pushing aside the very difficult decision of what the function is going to be called, or worrying for now what the argument names and specific values should be.
Statically typed languages force programers to do this, whereas dynamically typed languages assume the input and output types will be explained in documentation (resulting in lots of unuseable code which not even the original author can figure out what goes in or out later).
Unlike most programming languages where the signature looks something like Number Number -> Number indicating
a return value the function substitutes itself into, Prolog has input and output values, but the basic
concept remains the same.
Learning Barbara Liskov’s theory of type hierarchy was a revelation to me, and the first thing I tend to do when learning a new language is draw a diagram such as the one below for SWI Prolog.
any
├── atomic
│ ├── number
│ │ ├── integer
│ │ │ ├── nonneg % Integer >= 0
│ │ │ ├── positive_integer % Integer > 0
│ │ │ ├── negative_integer % Integer < 0
│ │ │ └── between(U, L) % Integer >= L, Integer =< U
│ │ └── float
│ │ ├── rational % includes integers
│ │ └── between(U, L) % Float >= L, Float =< U
│ ├── text
│ │ ├── atom
│ │ │ ├── symbol % with or without single quotes
│ │ │ ├── char % Atom of length 1
│ │ │ ├── code % Unicode point
│ │ │ └── blob
│ │ │ └── stream
│ │ └── string % double or single quoted
│ └── boolean
└── compound
├── callable % Can also be functor/0 symbol
├── list ; proper_list
│ ├── list_or_partial_list
│ ├── list(Type)
│ ├── chars
│ └── codes
├── tree ; graph % Not defined as a formal type
│ ├── cyclic
│ └── acyclic
└── dict
Jan Wielemaker in the aforementioned Discourse thread pointed out a number of errors and omissions in my above ASCII artwork. I’ll try and improve it in due course.
About the most comprehensive list of types in SWI Prolog is given in its must_be(+Type, @Term) documentation.
A general rule of thumb is to be as specific as possible with a variable’s type.
For instance, in my example, symbol is better than atom for the
Game variable. Better yet might be to say module_name. I’m not sure if SWI Prolog has anything similar to
Erlang’s dialyzer which uses its -spec and -type declarations
for more than just documentation. But here the Argname:Type declarations are purely descriptive, and can be
any text.
It’s better to stick to predefined types with their associated library of built-ins. For instance Predicates that operate on strings, lists, etc.
Meaningful names for predicates
Writing a signature and a purpose statement first often helps settle on the right name since it should indicate to users what types it consumes and produces, and be a one word summary of its purpose statement.
To be a legal predicate name, besides not clashing with an existing built-in
it has to pass the test atom(@Term),
ie it must start with a lower case letter, or be entirely made of non-alphanumeric characters like ==>, ‘+’ etc.
Illegal names include:
- Ending with a question mark (as is the convention for predicates in Lisp) eg
atom(foo?).createsERROR: Syntax error: Operator expected...messages. Same problem withatom(foo!). - Kebab-case eg
atom(foo-bar).returns false. The convention in Prolog appears to be snake_case. - Starting with a capital letter or underscore which are reserved for variables.
- Starting with a number
Good style in any language is probably to follow the conventions used in built-in predicates, and here are some examples:
- Predicate to test type
- atom(@Term), there is a full list at Verify Type of a Term which doubles as a handy reference for SWI Prolog’s types.
- Type converters
- number_string(?Number, ?String)
The symetry offered by Prolog’s bidirectionality shines with these. Conventional languages need
to_number(String)andto_string(Number)to achieve what Prolog does with one predicate.
Argument mode indicators
Something that makes Prolog unconventional is that instead of being based functional calculus as in f(x) → y where the called function with arguments substitutes itself into a return value, it mimics predicate logic with p(+X, -Y), where things calculated are output arguments. Note that the + prefix for inputs and - prefix for outputs are argument mode indicators that only appear in documentation, not the code itself.
Something that tripped me up was the module system’s meta-predicate
syntax also uses +, -, ?, and :, along with some additional symbols *, ^, //, and digits 0..9. The two are related,
but serve different purposes.
The source code for the apply.pl module illustrates the difference:
:- meta_predicate
include(1, +, -),
...
%! include(:Goal, +List1, ?List2) is det.
%
% Filter elements for which Goal succeeds. True if List2 contains
% those elements Xi of List1 for which call(Goal, Xi) succeeds.
...
To illustrate what’s going on, lets use this example:
?- include(atom, [Var, 3, true, myname], Atoms).
Atoms = [true, myname].
Note I call the filter :Goal atom(@Term) without its
single argument. The 1 in the meta_predicate declaration for include indicates a partial whose last argument
will be supplied is expected. A subtlety here is that it doesn’t mean :Goal has to have arity 1, only that its
final argument is omitted. Let me use succ(?Int1, ?Int2)
to illustrate:
?- include(succ(1), [1,2,3,4], L).
L = [2].
The + in the second argument of both the meta_predicate declaration and documentation indicates a nonvar
— ie input argument — is expected here. A subtlety in the mode indicator notation is ++ can be used
to indicate the following is not allowed:
?- include(atom, [Var, 3, true, myname|_], Atoms).
Atoms = [true, myname] ;
Atoms = [true, myname] ;
Atoms = [true, myname] ;
Atoms = [true, myname] ;
Atoms = [true, myname] .
If include was rewritten as include(:Goal, ++List1, ?List2) is det. the notation would indicate there was a guard
against something like the above making it nondet.
The question mark prefix in the third argument indicates this can be used to test a result instead of generating it:
?- include(atom, [Var, 3, true, myname], [true, myname]).
true.
?- include(atom, [Var, 3, true, myname], [foo, bar]).
false.
Though ? and * (which are equivalent) are in the list of meta_predicate symbols, - is used in include’s code,
presumably because the return list needs to be generated irrespectively of whether it will be returned or checked
against a provided answer. The ability to often do assertion tests by giving an output argument an expected value is
a bonus in Prolog.
Ordering Arguments
Using illustrative names for arguments helps improve documentation. It’s also important to put arguments in the right order. Richard O’Keefe in The Craft of Prolog (p14 in the copy I have) suggested this precedence for argument ordering:
- Templates (eg as in findall(+Template, :Goal, -Bag)) come first.
- Meta-arguments, as in :Goal in maplist(:Goal, ?List1, ?List2) and
findall/3above come next. - Streams, as created by open(+SrcDest, +Mode, –Stream) are third. Good style is to place these within setup_call_cleanup(:Setup, :Goal, :Cleanup). Since Stream is the output of
open/3, it’s not a good example. Whatever predicate uses it (ie the second argument of setup_call_cleanup) would follow this convention. - Selectors or indices as in arg(?Idx, +Term, ?Value).
- Collections as in Lists, Dictionaries, and context arguments like
context_name(A,B,C,D,…). - Input arguments which the predicate solves or tests for (which could be bidirectional, doubling as outputs).
- Outputs come last (which in the case of bidirectional predicates may sometimes be inputs. O ‘Keefe suggests ordering bidirectional arguments by which is most commonly used input and output).
While many of these are just stylistic, it’s very important for outputs to come last and inputs to come second last for predicates to work as second_order functions for the apply family of predicates listed in library(apply) as in maplist/3, include/3, exclude/3 etc.
Predicate behaviour
Whether a predicate is det, semidet or nondet is fairly confusing. nondet means there are alternatives, or choice points in Prolog jargon.
Unless care is taken writing Prolog’s conditionals — as in several predicates with the same name and arity of which only one is expected to match a given call — a predicate that is supposed to be det (ie only return one answer) can inadvertently turn out to be nondet.
PLUnit assumes you want your predicate to be det, and Writing the test body explains the options for testing nondet and semidet predicates.
How?
Once you know the types you want your predicate to consume and produce, finding a built-in with the same signature simplifies Step 4, templating. I’ve found SWI Prolog’s listing(:What) a huge boon, leading to built-ins that do exactly what I want, or at least providing handy skeletons to help code what I want.
There’s also edit(+Specification) which brings up the original code in a text editor, which by default is an Emacs-clone Xpce which comes included with SWI Prolog.
The web page PLDoc generates also has icons which let you view the source code or load it into Xpce.
Debugging tips
When in doubt, print it out has long been my favourite Prolog debugging technique, and for many years I would comment in-and-out format(+Format, :Arguments) statements to figure out why my code wasn’t producing the correct answers. Luckily I discovered debug(+Topic, +Format, :Args) which achieves the same thing, but with the magic of debug(+Topic) saves the need to find and comment in or out format statements.
Remember to compile production code
Once your SWI Prolog script is “production ready”, its speed can often greatly be improved with qcompile(:File).
If I run qcompile("bestmove.pl"). in the swipl repl, a file called bestmove.qlf appears in my subdirectory. Then editing
my test and module clients to use consult("bestmove.qlf") or load_module(“bestmove.qlf”) can often speed things up dramatically.